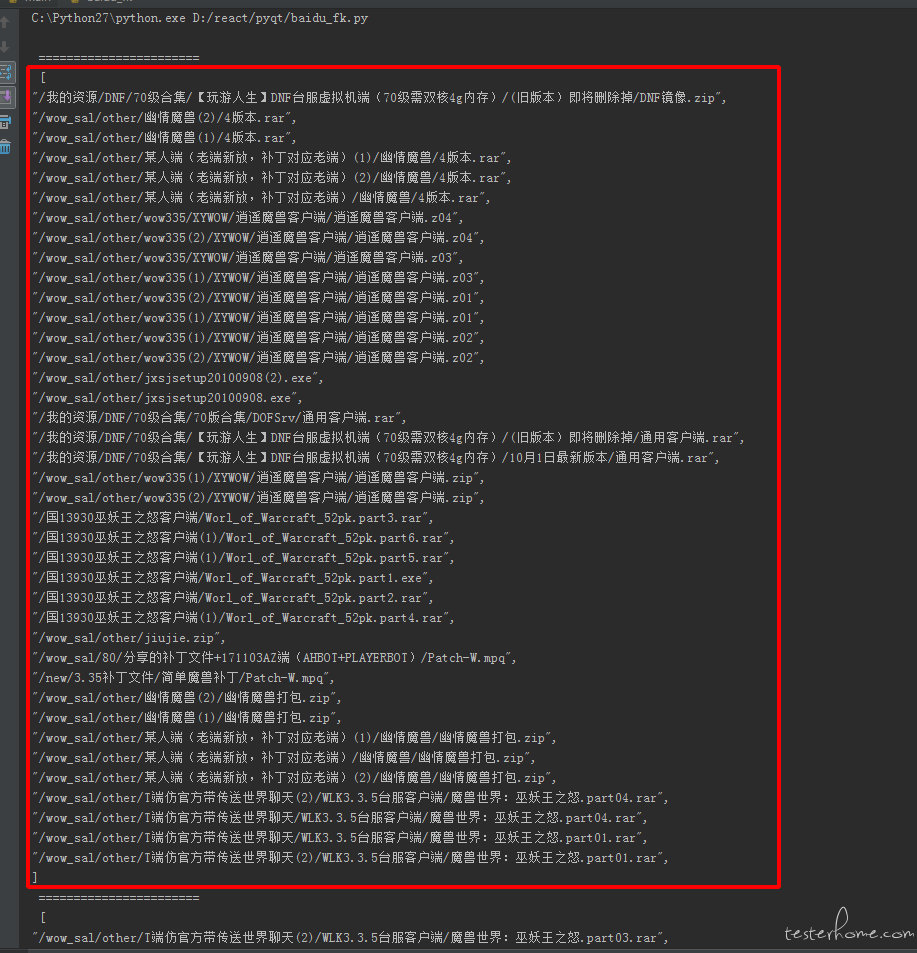
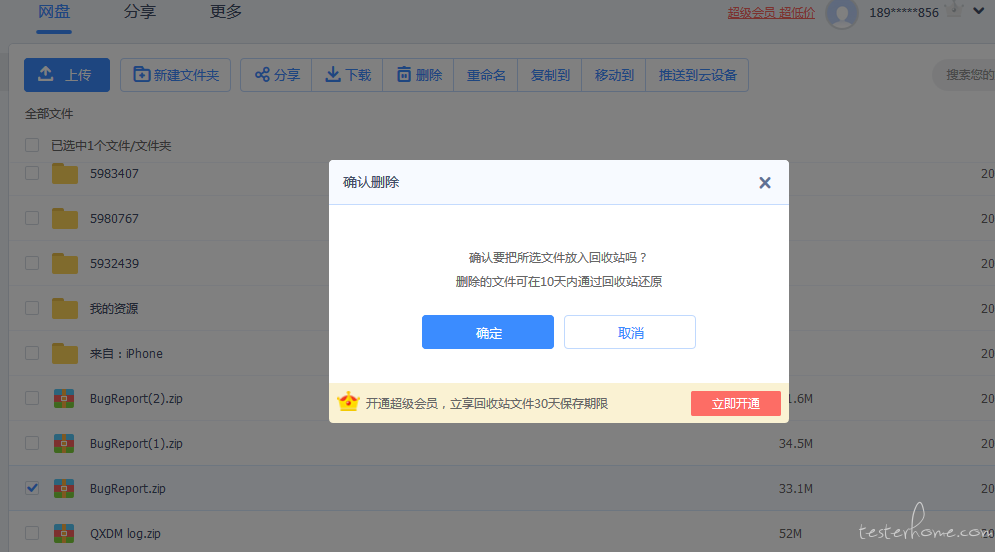
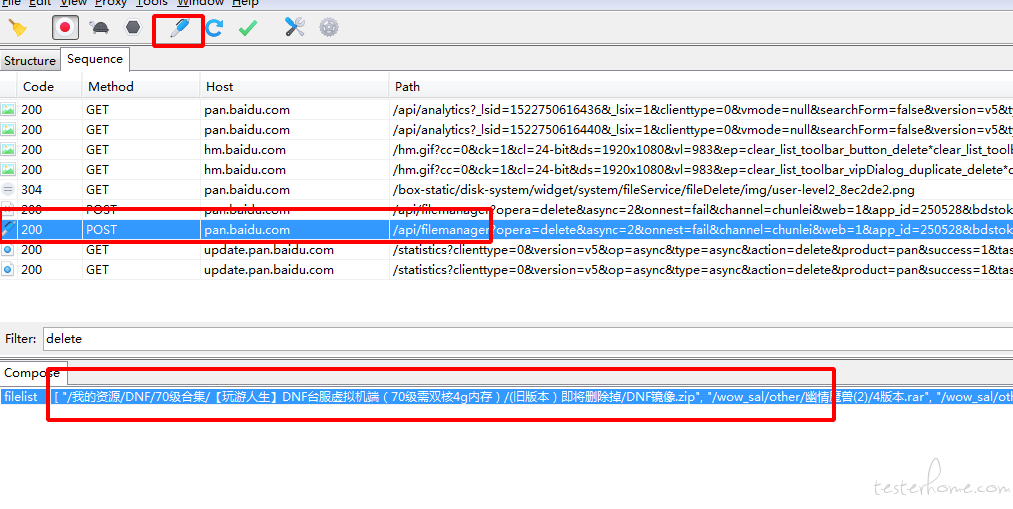
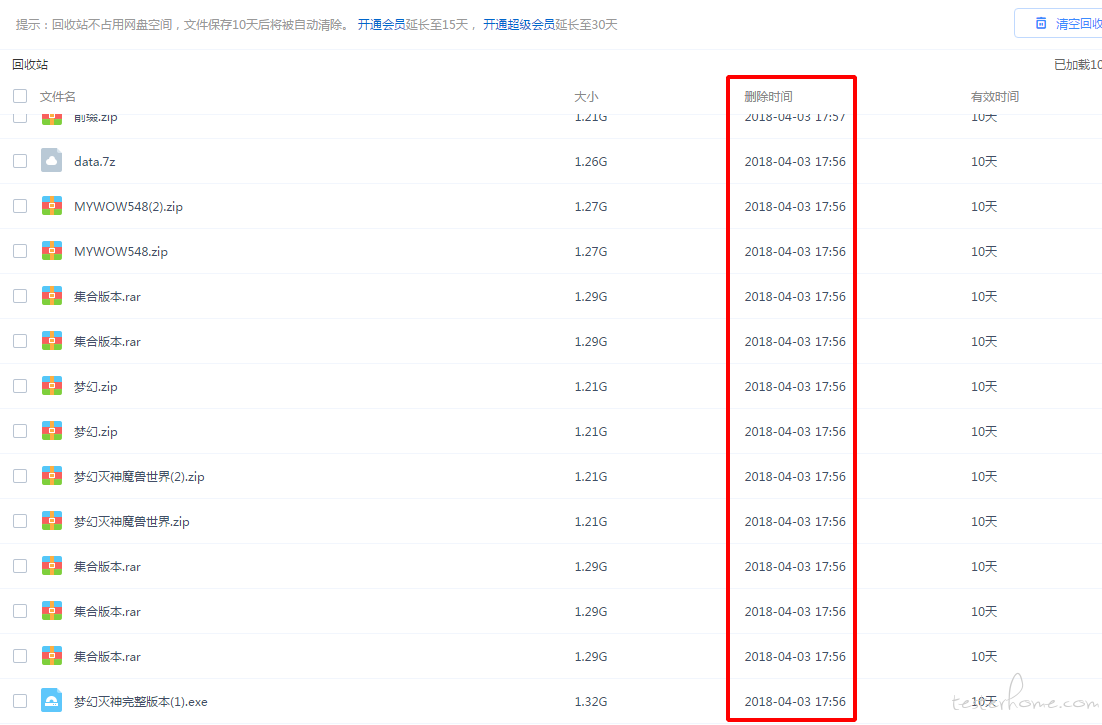
defget_need_delete_paths(): withopen('baidu.json', 'r') as f: data = json.loads(f.read()) a = 1 lists = data["list"] need_delete_paths = [] forlistin lists: list_data = list["data"] for i inrange(1, len(list_data)): need_delete_paths.append(list_data[i]["path"])
for path in need_delete_paths: if a == 1: print"\n ======================= \n [" if a - 40 == 0: a = 1 print"]\n ======================= \n [" a = a + 1 print'"'+path+'",' print"]\n ======================= \n"