1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
from selenium import webdriver
import requests,json,time
now_title = ''
browser = webdriver.Firefox()
while True:
t = time.time()*1000
curr_time = int(t)
url = 'http://140.143.49.31/api/ans2?key=zscr&wdcallback=jQuery3210029295865213498473_1516703643922&_='+str(curr_time)
headers = {
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Accept': '*/*',
'x-wap-profile': 'http://wap1.huawei.com/uaprof/HUAWEI_H60_L01_UAProfile.xml',
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.4.2; H60-L01 Build/HDH60-L01) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/30.0.0.0 Mobile Safari/537.36 SogouSearch Android1.0 version3.0 AppVersion/5909',
'Referer': 'http://nb.sa.sogou.com/',
'Accept-Encoding': 'gzip,deflate',
'Accept-Language': 'zh-CN,en-US;q=0.8',
'X-Requested-With': 'com.sogou.activity.src'
}
req = requests.get(url,headers=headers)
response = req.text
data = response
data = data[data.rfind('({',1):-1]
data = data[1:len(data)]
try:
data = json.loads(data)
except:
continue
result = data["result"]
answer = result[1]
answer = json.loads(answer)
answer_title = answer["title"]
if now_title != answer_title:
count = 10
now_title = answer_title
answer_answers = answer["answers"]
answer_result = answer["result"]
default_title = '大家'
default_title = default_title.decode('utf-8')
if default_title in now_title:
print '还没开放'
else:
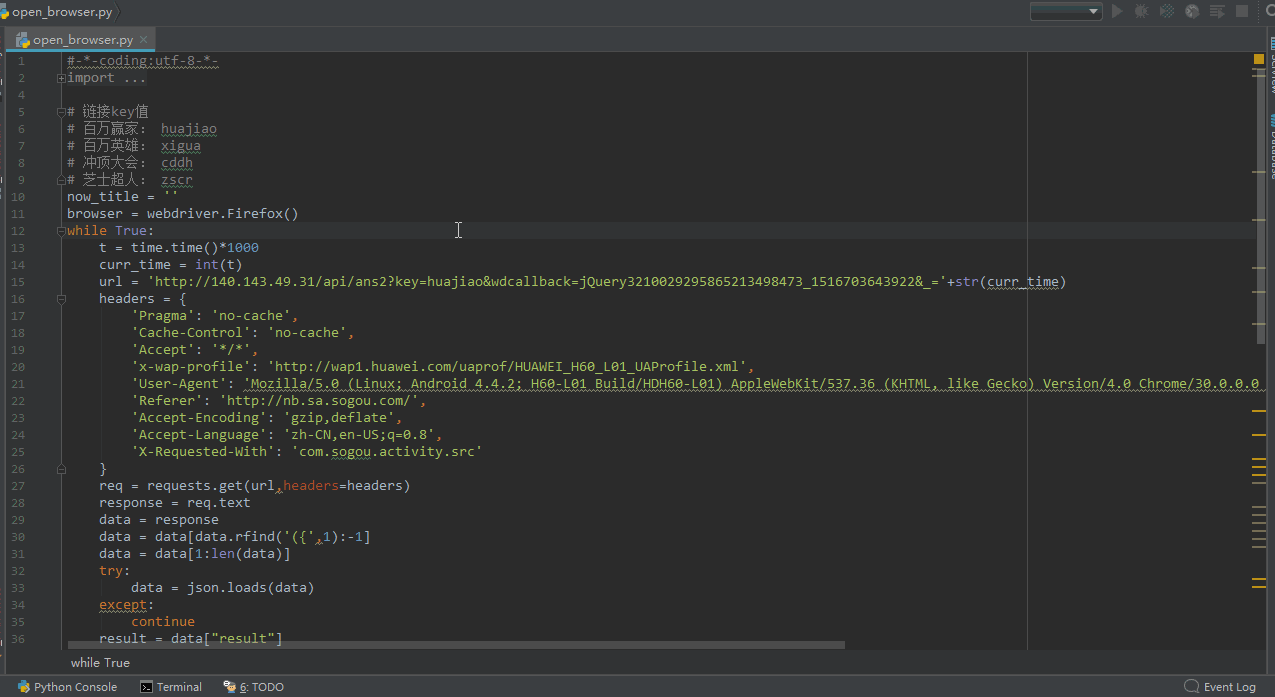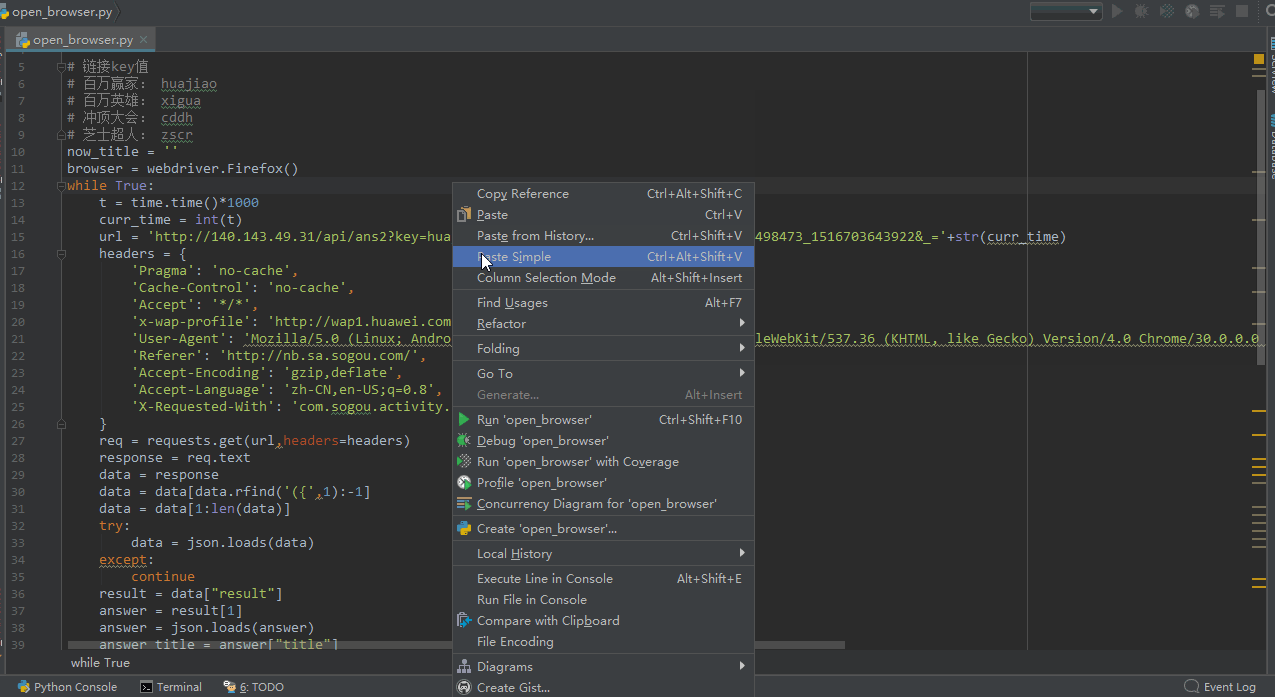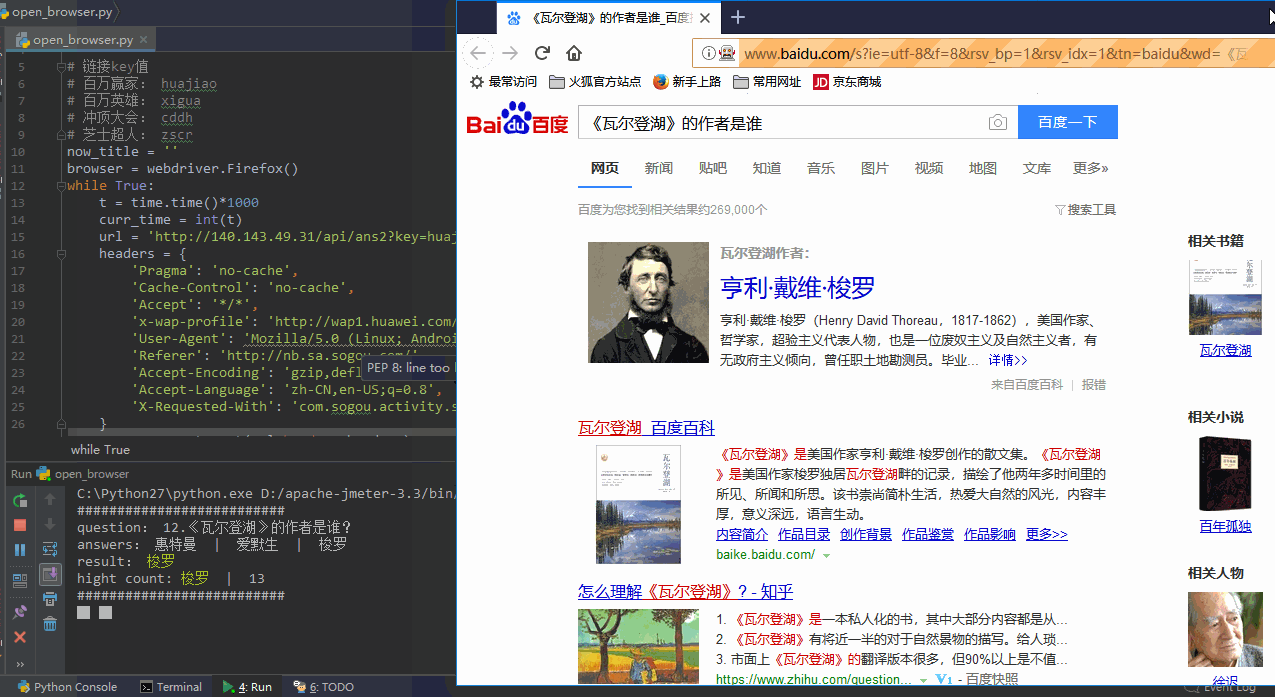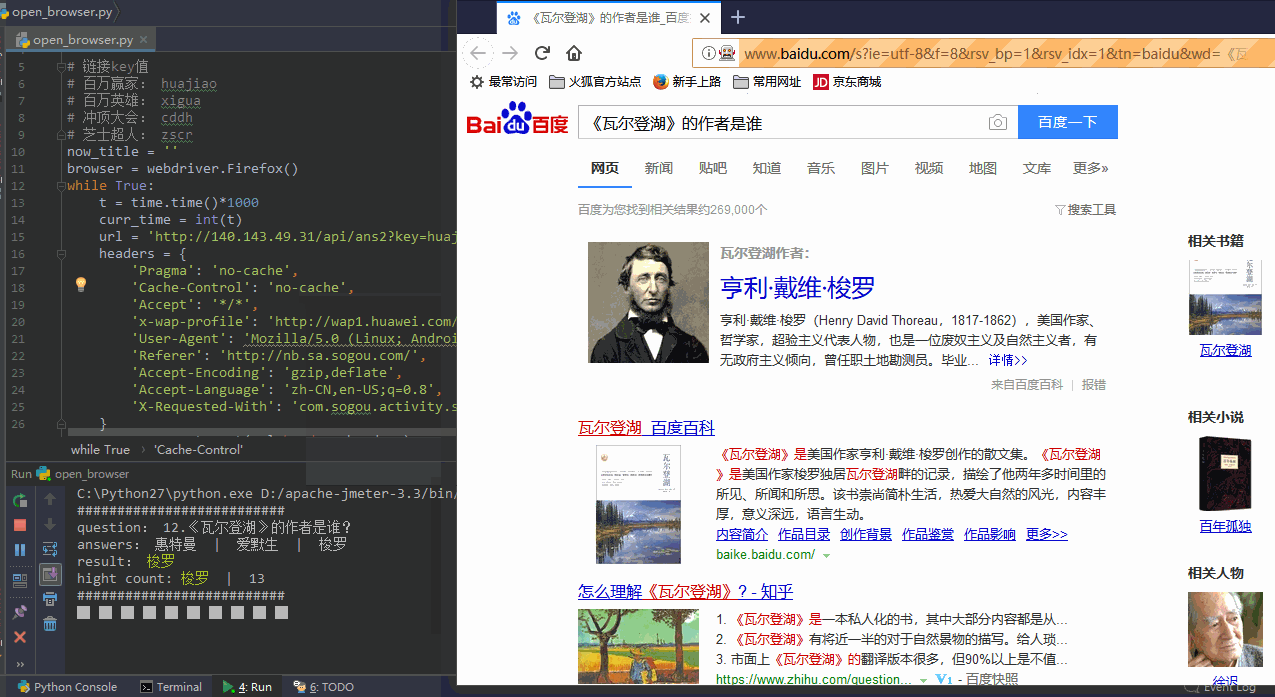
print "##########################"
print "question:",answer_title
print "answers:",answer_answers[0],' | ',answer_answers[1],' | ',answer_answers[2]
print "result:", '\033[5;32;2m%s\033[0m' % answer_result
search_url = "http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=" + answer_title[answer_title.rfind('.',1)+1:len(answer_title) - 1]
html = requests.get(search_url)
html = html.text
dict_count = {}
dict_count[answer_answers[0]] = {'count':html.count(answer_answers[0])}
dict_count[answer_answers[1]] = {'count':html.count(answer_answers[1])}
dict_count[answer_answers[2]] = {'count':html.count(answer_answers[2])}
dict = sorted(dict_count.iteritems(), key=lambda d: d[1]['count'], reverse=True)
if dict[0][1]['count']>0 and dict[0][1]['count'] != dict[1][1]['count'] :
print "hight count:", '\033[5;32;2m%s\033[0m' % dict[0][0], " | ", dict[0][1]['count']
print "##########################"
browser.get(search_url)
if count > 0:
print '▇',
count -= 1
|